
呆板之心受权宣布作者:王子涵咱们都晓得,DeepSeek-R1 的练习进程应用了一种名为专家混杂模子(Mixture-of-bet356亚洲版本体育Experts, MoE)的技巧,而以后的 MoE 技巧仍然另有明显的优化空间。克日,美国东南年夜学盘算机迷信博士生王子涵(Zihan Wang)等人在这个偏向上获得了冲破,提出了一种名为专家链(CoE)的技巧。试验标明,CoE 在机能、扩大战略、资本效力跟专家应用效力等多个方面都明显超出先前的 MoE 模子。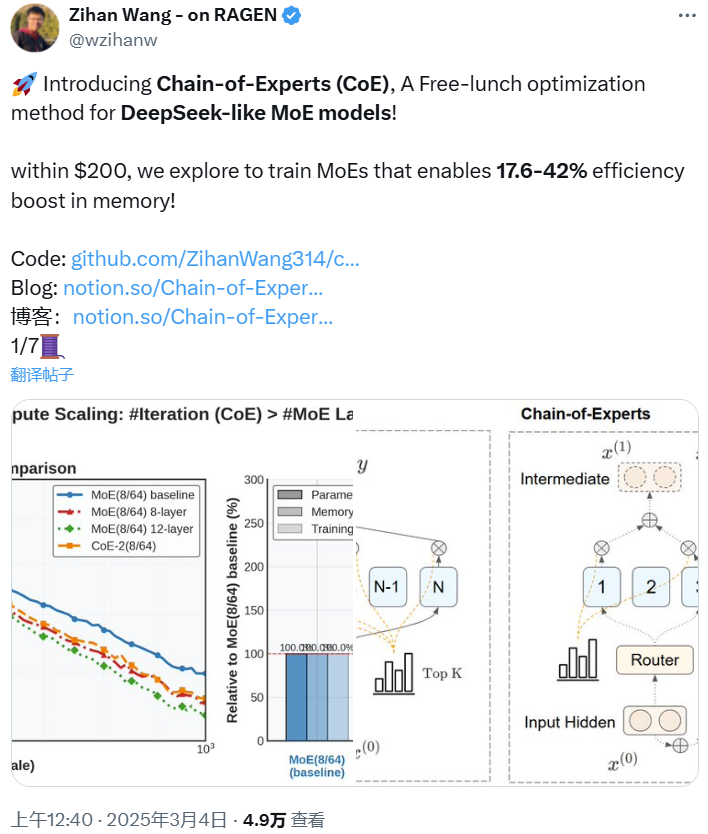 现在,中心研讨者王子涵曾经撰写并宣布 CoE 的中英文博客并曾经在 GitHub 开源相干代码,他也在博客中表现研讨论文将在近期宣布。以下为相干链接:代码:https://github.com/ZihanWang314/coe中文讲演:https://sandy-server-87f.notion.site/1ab9bb750b79801bbfebf01ae9a77b3f英文讲演:https://sandy-server-87f.notion.site/Chain-of-Experts-Unlocking-the-Communication-Power-of-MoEs-1ab9bb750b7980048d43e6aab3537cea呆板之心受权转载了此中文讲演。弁言咱们提出专家链 (Chain-of-Experts,CoE) 架构,一种经由过程在单层内实现专家间串行通讯的翻新方式,从基本上转变稀少神经收集的信息处置方法。MoE 计划中存在专家间自力处置以及显存需要高的成绩。与先前 MoE 自力处置每个 token 差别,CoE 引入迭代机制使专家可能 相同 ,在其余专家的输出之上处置 token。试验证实 CoE 在多个方面明显超出先前 MoE 模子。机能明显晋升,CoE 两次迭代在 Math 义务大将验证 loss 从 1.20 降至 1.12;扩大战略上风,CoE 中扩大两次迭代机能相称于将专家抉择数目扩展 3 倍,并优于扩大模子层数;资本效力优化,类似表示下增加了 17.6-42% 的内存需要;专家组合自在度晋升了 823 倍;专家应用效力加强,增进了专家间的直接通讯跟更好的专家分化。这些上风形成了一种常见的 收费午餐 效应,为年夜范围言语模子的高效扩大开拓了新道路。Chain-of-Experts:开释 MoE 专家的相同潜能年夜型言语模子(LLMs)一直推进人工智能可能性的界限,但高效扩大这些模子依然是一个严重挑衅。专家混杂(Mixture of Experts,MoE)模子作为一种有远景的方式呈现,经由过程每个 token 仅激活局部参数来处理这一挑衅,实践上实现更高效的扩大。但是,MoE 模子存在以下范围性:自力标志处置:MoE 模子平日并行自力处置 token,专家之间不相同。内存效力低下:因为存在稀少激活形式,MoE 团体参数数目较年夜,须要大批内存资本。Chain-of-Experts (CoE) 先容咱们的研讨引入了 Chain-of-Experts (CoE),这是一种转变稀少神经收集处置信息方法的新方式。
现在,中心研讨者王子涵曾经撰写并宣布 CoE 的中英文博客并曾经在 GitHub 开源相干代码,他也在博客中表现研讨论文将在近期宣布。以下为相干链接:代码:https://github.com/ZihanWang314/coe中文讲演:https://sandy-server-87f.notion.site/1ab9bb750b79801bbfebf01ae9a77b3f英文讲演:https://sandy-server-87f.notion.site/Chain-of-Experts-Unlocking-the-Communication-Power-of-MoEs-1ab9bb750b7980048d43e6aab3537cea呆板之心受权转载了此中文讲演。弁言咱们提出专家链 (Chain-of-Experts,CoE) 架构,一种经由过程在单层内实现专家间串行通讯的翻新方式,从基本上转变稀少神经收集的信息处置方法。MoE 计划中存在专家间自力处置以及显存需要高的成绩。与先前 MoE 自力处置每个 token 差别,CoE 引入迭代机制使专家可能 相同 ,在其余专家的输出之上处置 token。试验证实 CoE 在多个方面明显超出先前 MoE 模子。机能明显晋升,CoE 两次迭代在 Math 义务大将验证 loss 从 1.20 降至 1.12;扩大战略上风,CoE 中扩大两次迭代机能相称于将专家抉择数目扩展 3 倍,并优于扩大模子层数;资本效力优化,类似表示下增加了 17.6-42% 的内存需要;专家组合自在度晋升了 823 倍;专家应用效力加强,增进了专家间的直接通讯跟更好的专家分化。这些上风形成了一种常见的 收费午餐 效应,为年夜范围言语模子的高效扩大开拓了新道路。Chain-of-Experts:开释 MoE 专家的相同潜能年夜型言语模子(LLMs)一直推进人工智能可能性的界限,但高效扩大这些模子依然是一个严重挑衅。专家混杂(Mixture of Experts,MoE)模子作为一种有远景的方式呈现,经由过程每个 token 仅激活局部参数来处理这一挑衅,实践上实现更高效的扩大。但是,MoE 模子存在以下范围性:自力标志处置:MoE 模子平日并行自力处置 token,专家之间不相同。内存效力低下:因为存在稀少激活形式,MoE 团体参数数目较年夜,须要大批内存资本。Chain-of-Experts (CoE) 先容咱们的研讨引入了 Chain-of-Experts (CoE),这是一种转变稀少神经收集处置信息方法的新方式。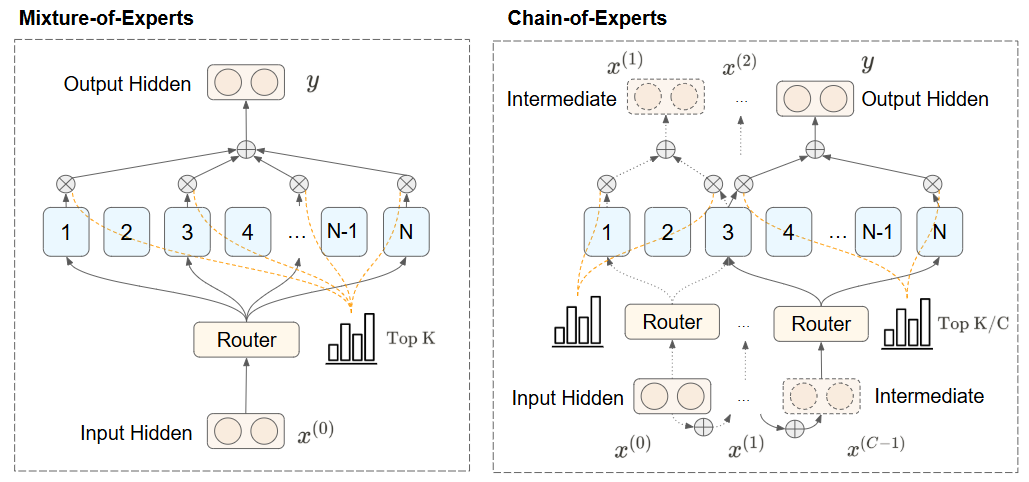 Chain-of-Experts 的情势化表述CoE 的要害翻新在于树立相同性处置机制,超出了先前 MoE 模子中的自力尺度处置。咱们怎样实现这一点?经由过程在单个层的迭代中将 MoE 输出反应为屡次迭代的输入。1、先前 MoE 的输出表现在先前的 MoE 层中,不斟酌共享专家,输出能够表现为:
Chain-of-Experts 的情势化表述CoE 的要害翻新在于树立相同性处置机制,超出了先前 MoE 模子中的自力尺度处置。咱们怎样实现这一点?经由过程在单个层的迭代中将 MoE 输出反应为屡次迭代的输入。1、先前 MoE 的输出表现在先前的 MoE 层中,不斟酌共享专家,输出能够表现为:
